Chi-Wei Hsiao, Cheng Sun, Min Sun, Hwann-Tzong Chen
ICCV 2021,
[paper]
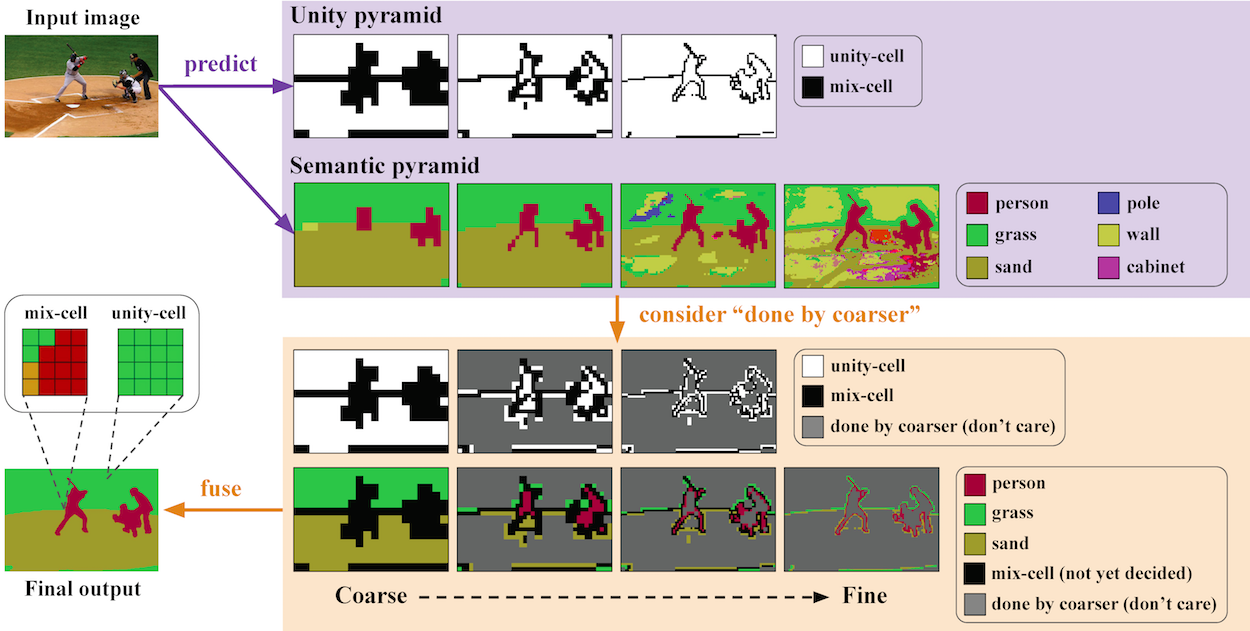
We present a novel pyramidal output representation to ensure parsimony with our "specialize and fuse" process for semantic segmentation. A pyramidal "output" representation consists of coarse-to-fine levels, where each level is "specialize" in a different class distribution (e.g., more stuff than things classes at coarser levels). Two types of pyramidal outputs (i.e., unity and semantic pyramid) are "fused" into the final semantic output, where the unity pyramid indicates unity-cells (i.e., all pixels in such cell share the same semantic label). The process ensures parsimony by predicting a relatively small number of labels for unity-cells (e.g., a large cell of grass) to build the final semantic output. In addition to the "output" representation, we design a coarse-to-fine contextual module to aggregate the "features" representation from different levels. We validate the effectiveness of each key module in our method through comprehensive ablation studies. Finally, our approach achieves state-of-the-art performance on three widely-used semantic segmentation datasets -- ADE20K, COCO-Stuff, and Pascal-Context.
Cheng Sun, Chi-Wei Hsiao, Ning-Hsu Wang, Min Sun, Hwann-Tzong Chen
CVPR 2021 Oral,
[paper]
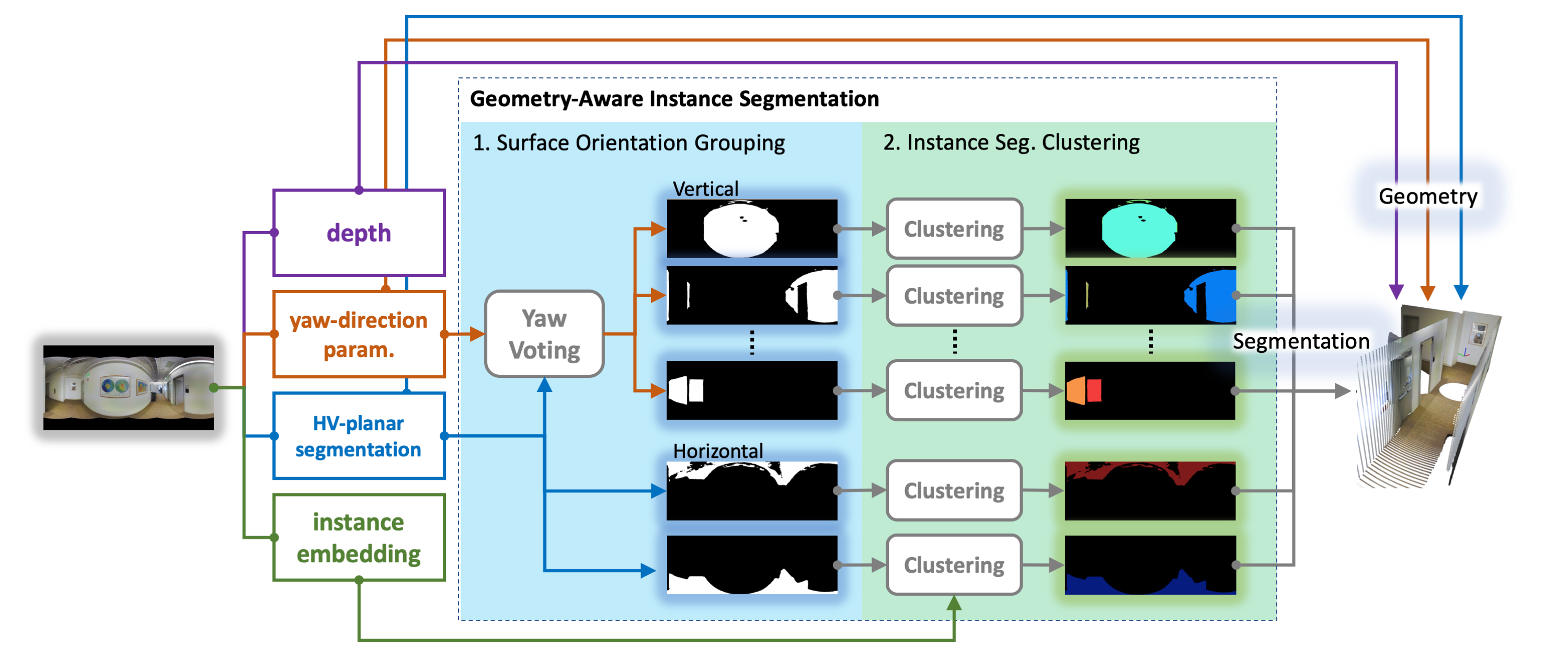
Indoor panorama typically consists of human-made structures parallel or perpendicular to gravity. We leverage this phenomenon to approximate the scene in a 360-degree image with (H)orizontal-planes and (V)ertical-planes. To this end, we propose an effective divide-and-conquer strategy that divides pixels based on their plane orientation estimation; then, the succeeding instance segmentation module conquers the task of planes clustering more easily in each plane orientation group. Besides, parameters of V-planes depend on camera yaw rotation, but translation-invariant CNNs are less aware of the yaw change. We thus propose a yaw-invariant V-planar reparameterization for CNNs to learn. We create a benchmark for indoor panorama planar reconstruction by extending existing 360 depth datasets with ground truth H&V-planes (referred to as “PanoH&V” dataset) and adopt state-of-the-art planar reconstruction methods to predict H&V-planes as our baselines. Our method outperforms the baselines by a large margin on the proposed dataset.
Cheng Sun, Chi-Wei Hsiao, Min Sun, Hwann-Tzong Chen
CVPR 2019,
[paper]
[code]
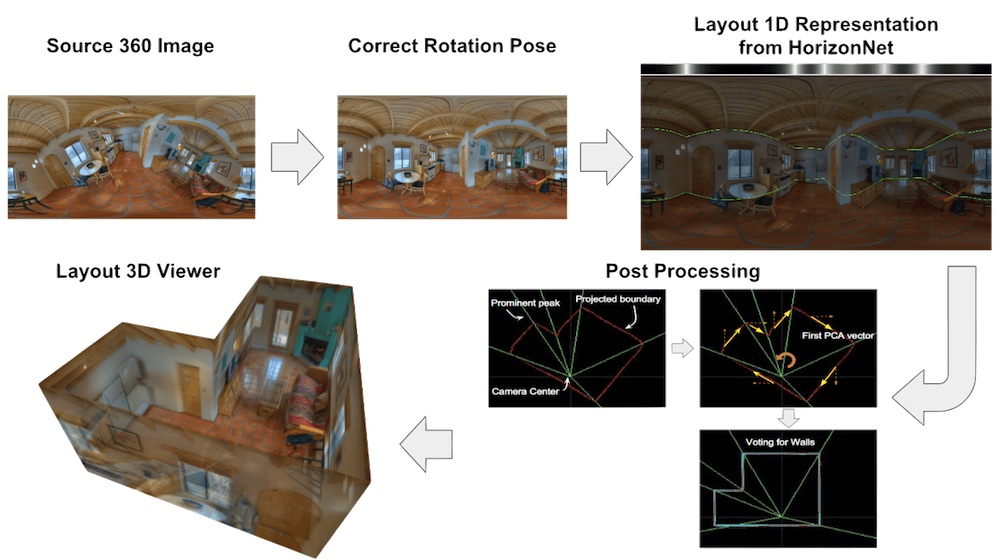
We present a new approach to the problem of estimating the 3D room layout from a single panoramic image. We represent room layout as three 1D vectors that encode, at each image column, the boundary positions of floor-wall and ceiling-wall, and the existence of wall-wall boundary. The proposed network, HorizonNet, trained for predicting 1D layout, outperforms previous state-of-the-art approaches. The designed post-processing procedure for recovering 3D room layouts from 1D predictions can automatically infer the room shape with low computation cost—it takes less than 20ms for a panorama image while prior works might need dozens of seconds. We also propose Pano Stretch Data Augmentation, which can diversify panorama data and be applied to other panorama-related learning tasks. Due to the limited data available for non-cuboid layout, we relabel 65 general layout from the current dataset for finetuning. Our approach shows good performance on general layouts by qualitative results and cross-validation.

Chi-Wei Hsiao, Cheng Sun, Min Sun, Hwann-Tzong Chen
[paper]
This paper proposes a new approach, Flat2Layout, for estimating general indoor room layout from a single-view RGB image whereas existing methods can only produce layout topologies captured from the box-shaped room. The proposed flat representation encodes the layout information into row vectors which are treated as the training target of the deep model. A dynamic programming based postprocessing is employed to decode the estimated flat output from the deep model into the final room layout. Flat2Layout achieves state-of-the-art performance on existing room layout benchmark. This paper also constructs a benchmark for validating the performance on general layout topologies, where Flat2Layout achieves good performance on general room types. Flat2Layout is applicable on more scenario for layout estimation and would have an impact on applications of Scene Modeling, Robotics, and Augmented Reality.

Appier (ML Scientist Intern)
content-based recommendation system

Academia Sinica (Intern)
